Members Column メンバーズコラム
ビッグデータの活用をちょっと考える
福山浩 (パナソニック(株)) Vol.222
KNSメンバーの福山です。
大阪の会社員です。
当社もここ2年大きな改革があり、私のようにぼ~っと会社生活を続けてきた
人間には大変な時代になりました。
人間の心理には楽観的な部分があるようです。避難警報が出ても我家は大丈
夫と避難しない人がいますね。私には特にそんな心理が強く作用しているよう
で、暢気に会社生活を続けながら、「まあ、家は大丈夫だろう」なんて考える
迂闊な人間です。これまで対岸の火事のように見ていたことが、我が身に火の
粉が降りかかってからのこのこ騒ぎ出す始末で、困ったものです。
そんなこんなで、先日退職後のことを考えていたら、さて保険、貯蓄、年金
等々が会社任せで、個人で管理できていないことに気づきました。私が万一の
場合、どんな保険に入っているのか、年金がいつからどれくらいでもらえる
のか、どこに貯蓄しているのか等々、整理し家族で共有できていないことに気
づきました。この機会に整理しておきたいと思いたったのですが、まだやって
いません。
そんなことはさて置き。
改革と言えば、よく使われるのが「業務の見直し」というやつです。例えば業
務を見直す際には、下記のような手法・言葉を良く使います。
『三無主義』とは、 「無理(ムリ)・無駄(ムダ)、斑(ムラ)を排除
できないか」
『RIAL活動』とは、 「その仕事をなくせないか、なくしたらどうなるか」
『システム化』とは、 「有機的にまとめることはできないか」
『標準化』とは、 「誰にでも出来る仕事にならないか」
『マニュアル化』とは、「手順を明確にできないか」
『平準化』とは、 「仕事の繁閑をなくせないか」
『スケジュール化』とは、「仕事の流れをスムースにし手戻りが防げないか」
『コストダウン』とは、「不必要な費用がかかっていないか」
業務見直しの本質は何なのでしょう? どれをとっても当たり前のことしか言
っていませんね。しかしながら、『標準化』の例で言いますと、「何をしたり、
どうすれば標準化できるのか、どうなったら標準化できたことになるのか」を
イメージすることが大切ではないかと思うのです。言い換えれば、「誰にでも
出来る仕事」になったら、標準化できたということになるのでしょう。
『マニュアル化』も同様です。『マニュアル化』とは、マニュアルを作るこ
と手順をドキュメント化することと仮に間違って捕らえてしまえば、決してい
いマニュアルを作ることは出来ないと思います。『マニュアル化できていない』
とは、ドキュメントがないと言うことではなく、手順が明確になっていないと
言うことです。従って、『マニュアル化』とは、手順を明確化することであり、
それに最大のパワーを懸ける必要があると思います。『マニュアル化』と『ド
キュメント化』は、違うのです。『本質』とは、『本来の目的』を見失わない
ということでもあると思います。
話は変わりますが、最近ビッグデータが話題です。
今回はそのさわりとなる「ビッグデータ処理」の中で、”機械学習”の技術に
ついて機会がありましたので紹介したいと思います。
良品計画などが機械学習の技術を使ってビッグデータを処理し顧客の分類、パ
ターン化を行い、顧客に推奨商品を発信して売り上げ増加につなげていること
がある雑誌で紹介されていました。
唐突ですが、例えば仮にコンビニの店長になったら「何を、いつ発注すれば
よいのか」「どうやって売上をあげたらいいのか」悩むところです。いろいろ
と経験の積んだ店長なら、天気予報の情報から傘やドリンクの発注量を決める
とか、新製品のCMを見てその製品目当ての来客者にクロスセル対策を打つと
か、これまでの経験から蓄積されたノウハウを駆使して将来の施策につなげて
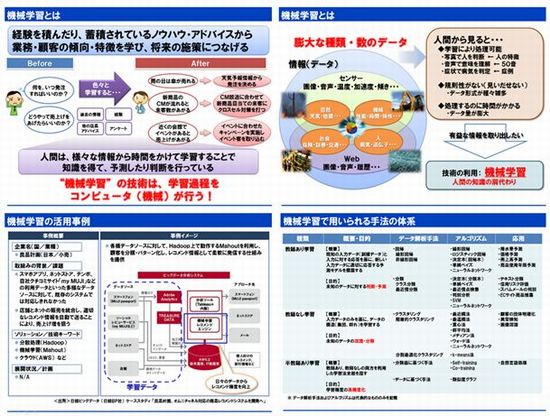
います。このように、人間は様々な情報から時間をかけて学習することで知識
を得て、予測したり判断を行っています。“機械学習”の技術は、この学習過
程をコンピュータ(機械)でやってみよう、ということです。
人間が言葉や常識を学習する過程を、機械(コンピュータ)に再現させるこ
とによって、コンピュータがデータの中から知識やルールを自動的に獲得でき
るようにすることです。過去のデータの中から導き出した知識やルールを、新
たに収集したデータに適用することで、そのデータの意味や属性を認識・分類
したり、未来に起きることを判断・予測したりできます。
種類としては、『教師あり学習』『教師なし学習』『半教師あり学習』とい
うのがあります。
『教師あり学習』は、項目間の関係を蓄積されているデータから導き出し、
その関係を利用して、判断や予測に用いるというものです。
例としては、天気、気温、湿度、消費電力の項目を持つ日別データ1年分を
用いて、天気、気温、湿度 と 消費電力の関係を機械学習によって導く。その
導かれた関係と天気予報の情報を用いて消費電力を予測し、発電量の調整をす
る、という感じです。したがって、目的としては、「未知のデータに対する判
断・予測」ということになるでしょう。
『教師なし学習』は、データ間の関係を、蓄積されているデータから導き出
し、その関係を利用してパターンの認識や分類に用いるといものです。
例としては、車に設置されているセンサ情報(加速度、ブレーキ回数、ハン
ドル操作など)を1000名分収集し、機械学習によってグループ分けをする。
各グループの特徴から運転パターンを診断し、グループ別にエコ運転のアドバ
イスするといった感じです。目的としては「未知のデータの認識・分類」とい
うことになるでしょうか。
『半教師あり学習』は、「学習精度の高精度化」を目的としているようです。
各種類とも、いくつかの解析手法、アルゴリズムを駆使してデータ間の関係や
分類を行っています。
ビッグデータという言葉が盛り上がっていますが、有益な分析結果を得るに
は試行錯誤が必要です。データを機械に学習させれば、有益な結果がすぐに出
力されるわけではないのです。パラメータや入力データを調整しながら、試行
錯誤する必要があります。また、データの整形や分析に応じた加工などが必要
でもあります。普通に生活していても、我々の情報は至るところで集められ分
析、解析が知らないところでどんどん進んでいるようです。願うのは、厳格な
情報管理の下、有効な情報が市民の生活に活用されることです。
